Since I'm going to be talking about two different types of models, one which is a language model and the other which is the language model's model of the context, I'm going to refer to language models as LMs in this post. I'm also still in the process of writing this. If you don't see source code in the next few months, or you want immediate access to source code, just shoot me an email :)
LMs are next token predictors. Through giving the language model a series of tasks in context, where the output of the task is a single token, we can understand the LM's predictions over all possible tokens, and understand how likely the LM thinks that a given token is the correct answer for the task.
Through this, we can also measure how much information we need to feed a LM to allow it to learn a task. If the correct answer for task $i$ is $x_i$, we give the LM $$ -\log(P_{i - 1}(x_i)) $$ where $p_i(x)$ is the probability the LM assigns to the token $x$ after the $i$th example. This is just the surprisal. Then, we can find the total amount of information given to the LM to learn the task to be $$ \sum_{i = 1}^{\infty} -\log(P_{i - 1}(x_i)) $$ Practically, the surprisal goes to zero very quickly if the LM is able to grasp the task, or the LM is never able to grasp the task, and no amount of information is sufficient.
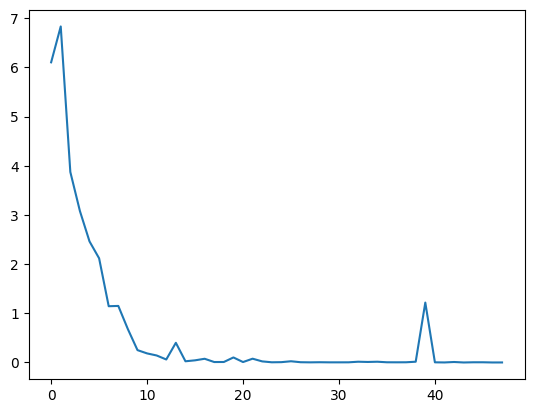
The following is a graph of LM surprisal to learn the task $f(x) = 2x + 3$, and we can see that the surprisal quickly drops to near zero, and very little extra information is given to the LM.
It is also interesting to understand how the language model updates it's priors. We only need to consider two cases: when the correct answer is $2x + 3$ and when the correct answer is not. We can call these two states $A$ and $B$ respectively. Initially, the model has some prior $\theta$ over the two, such that $P(A | \theta) + P(B | \theta)$ = 1. To give more granularity, we can say that $\theta_i$ is the prior after $i$ training examples.
Now, we can model this using Bayesian statistics.
| A | B | |
|---|---|---|
| Prior | $\theta_A$ | $\theta_B$ |
| Observation | $c$ | $1-c$ |
| Posterior | $\theta_A \times c$ | $\theta_B \times (1- c)$ |
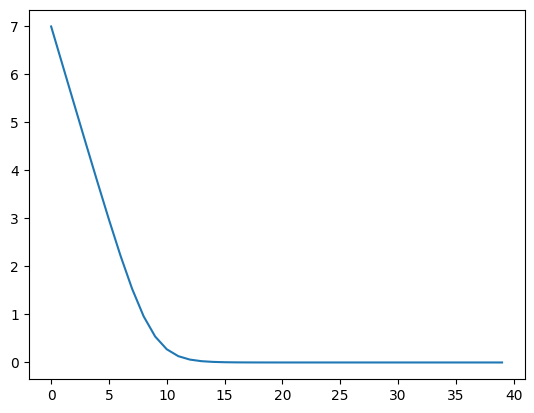
Our final probability for $\theta_{i +1, A}$ is $$ \frac{\theta_{i, A} \times c}{\theta_{i, A} \times c + \theta_{i, B} \times (1- c)} $$ Using this bayesian model to "simulate" the LM updating it's priors, we get a similar looking graph of surprisal over time!
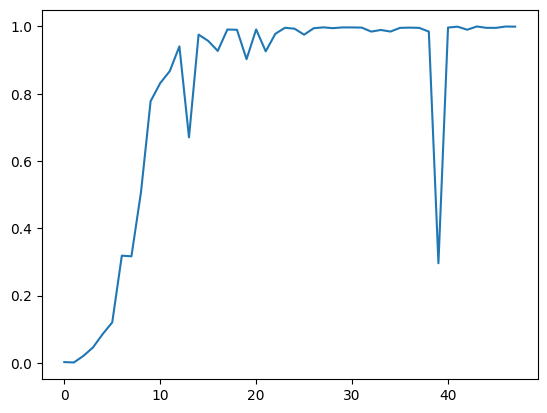
We can also look at the LM's probability of A:
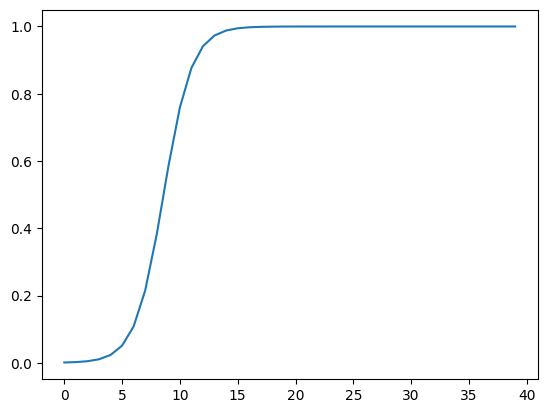
and compare this to our simulated, "bayesian" model:
Since language model outputs end up being softmaxed, we can work with logprobs. $$ \log(A) := \log(A) + \log(c) + norm $$
$$ \log(B) := \log(B) + \log(1 - c) + norm $$
$norm$ is some normalization constant that allows values to stay resonable. $A + B$ don't need to equal 1 since they get normalized at softmax.
Since the unembedding matrix is just a linear transformation on the logits, I hypothesize that the sizes of the features corresponding to $A$ and $B$ increase by this roughly constant amount during each example.
Logit lens and feature patching allow some more interesting insights. From logit lens, the model only crystalizes that the output token is an integer after the 20th layer. From patching, the model learns that $y \approx 2x$ around the 10th / 11th layer. I initially hypothesized that this was the result of the first forming some internal model of the task from the 11th to 16th layer, then converting this to the actual answer after the 20th layer. I don't think that this is true anymore.
I think that it's inappropriate to think of the idea that $y$ is always an integer and not some other token as a form of the model crystallizing it's answer. It seems more natural to think that this is just another feature that the model learns through ICL. To really test this, we can ablate different heads in the model. Specifically, L13H6, L13H27, L10H5 and L10H7.
The model has induction heads that attend to previous tokens. This likely allows for the model to say "here is where I need to learn from".