AI development is moving fast, and alignment research is not moving fast enough to deal with superintelligent models. This is a problem. One of the most proposed solutions to this is to implement and AGI pause or slowdown - make it take longer to build AGI, so alignment research can catch up in the meantime. However, it’s unclear to me how proponents of an AGI pause want this to be implemented.
To be clear, I’m not arguing that passing an AGI pause is out of the realm of possibility. It seems to me that the major American labs - OpenAI, Anthropic, Google, Meta - are all law-following organizations, and thus American AGI regulation would work on them. Similarly, I think that a US-China AGI pause is also possible. I instead write this post to discuss what such legislation might entail.
To examine my concerns with current pause proposals, I’ll consider PauseAI’s proposal1 for an AI pause.
Implement a temporary pause on the training of the most powerful general AI systems, until we know how to build them safely and keep them under democratic control.
I have a few major concerns with this:
- How do you understand when AGI is safe to build?
- To what extent do you risk an overhang, where AGI development quickly shoots up after the pause is lifted due to compute surplus or other factors?
- How do you ensure and understand when alignment research has caught up?
In addition, I have a few other wants during an AI pause that I’ll discuss.
Resuming AGI Development
Despite having good intentions, many environmental justice groups have shaped the world for the worse. Nuclear power has had it’s reputation soiled by anti-nuclear groups, causing a shift from nuclear power to more traditional fossil fuels. This cost many lives. Similarly, the increase in regulations on construction and industry that was driven by the environmental movement has caused meaningful suffering in the US - yet, at the time they proposed their regulation, they were probably entirely justified in their actions.
AGI, as imagined, will be a transformative technology. It’s unclear to me how AGI will affect the world economically, but enabling humanity more capability for intellectual work will without a doubt lead to progress.
In Optimal Timing to Build Superintelligence, Nick Bostrom tries to understand when to build superintelligence, given some priors over the progress of safety research and risk, presenting the following graph. I recommend reading the paper, which also examines “how to pause”, just like this post.
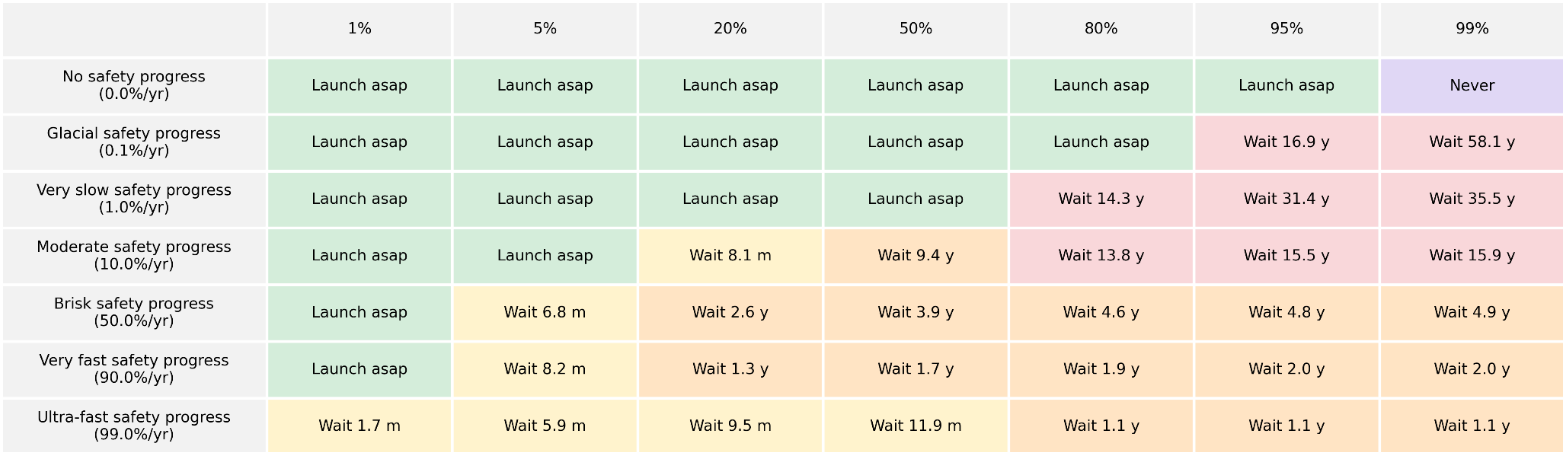
Even if I disagree with their specific numbers, I agree with their overall point - that intelligence is useful, and that we should build it when it’s safe enough to do so. One of my most significant worries with AGI pausing is that we extend the pause unreasonably long and subsequently miss out on all the benefits that come with it.
Furthermore, there are actors that may not comply with an international pause, such as AGI projects from rogue states, terrorist groups, and other non-state actors; despite not being real contenders in the current AGI race, after algorithmic improvements and compute access being more widespread, it seems feasible that in a few decades anyone could build towards AGI.
To this extent, we should almost guarantee that AGI development continues, unless alignment is entirely unfeasible. This is a risk that we should be willing to take. We should thus work towards understanding when we feel comfortable resuming AGI development.
This is really difficult - you’re dealing with unknown unknowns here, since it’s unclear what the landscape of alignment is going to look like. With access to the most recent models (Claude Opus 4.7 and Codex 5.4) at time of writing, there are enough gaps in our understanding of current models that making the road towards alignment is still unpaved.
However, I think all of this leaves room for optimism! The first pause will be huge and monumental, and it will require building further infrastructure to support coordination. Consider the following model:
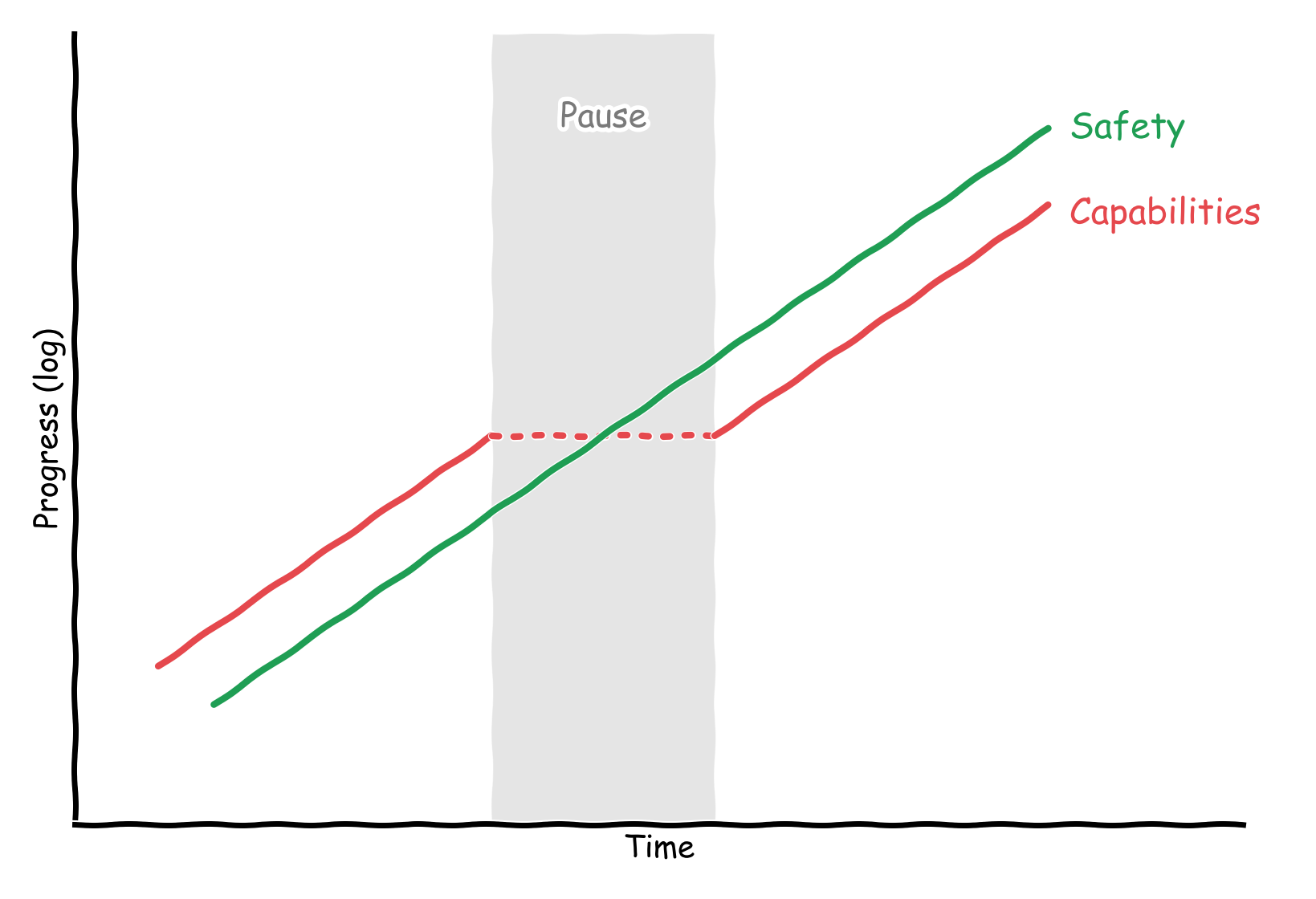
This models a true pause - there’s no capabilities overhang that causes the rate of capabilities progress to rapidly accelerate after the pause is lifted.
Furthermore, it assumes that the rate of safety progress is comparable to the rate of capabilities progress. It’s unclear to me whether this is reasonable - it seems clearly false at the moment, but this might be just because the field is less mature than ML as a whole - in a few years, the duration of a pause, will the rate of safety research catch up to capabilities progress? I’ll touch on this later.
As it stands, in the case of any pause, we would want for the safety research to have progressed as much as capabilities research and we would want for the rate of progress of safety research to be comparable to the rate of progress of capabilities research. To ensure that we can resume AGI development, we counterintuitively want to be more rigorous about pausing - setup infrastructure to measure the rate of safety progress, and also set up infrastructure to ensure that, if we resume AGI development too early, we have the optionality to pause again. If we make it so that we can pause again, we can unpause easier and bring about abundance faster.
Safety Overhangs
Even in a pause where labs cannot do experiments, labs should have access to huge amounts of compute. Claude Code and Codex and other products in their class have been hugely beneficial for the world, . Even if models don’t get any better, there are still many areas that are underexplored, and these models haven’t diffused across society sufficiently. Thus, we’d want to ensure that labs have the ability to continue serving their models.
Given current huge amounts of compute - and compute deployments that will continue - labs after the pause will have the ability to quickly scale up their training runs. If current progress can be accelerated by sheer scale, then we should expect progress to still hold during the pause.
As an oversimplification, AI progress can be approximated as a function of compute and algorithmic progress. EpochAI estimates that compute grows around $5 \times$ per year, and algorithmic progress grows around $3 \times$ per year. Thus, at first glance at least half of current progress is due to compute scaling. If labs no longer do training runs, but still stockpile compute, then we should expect progress to be around half of the current rate 2.
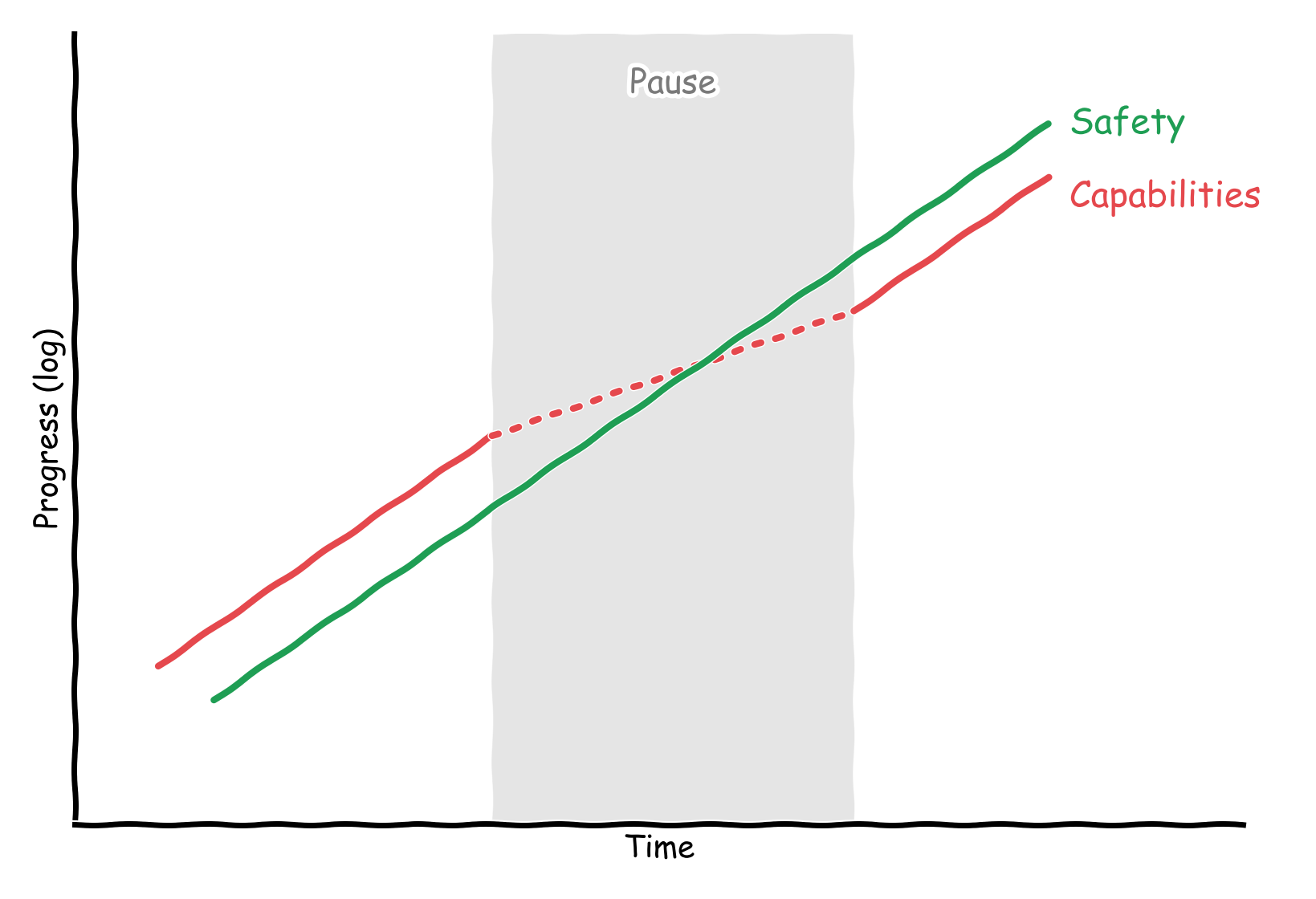
If safety progress is partly driven by capabilities progress, we should also expect for safety progress to slow down. In a pause, we could keep or increase the amount of compute allocated to safety, but it’s much easier to, for example, monitor a present model, than build monitors in anticipation of what future models will act like.
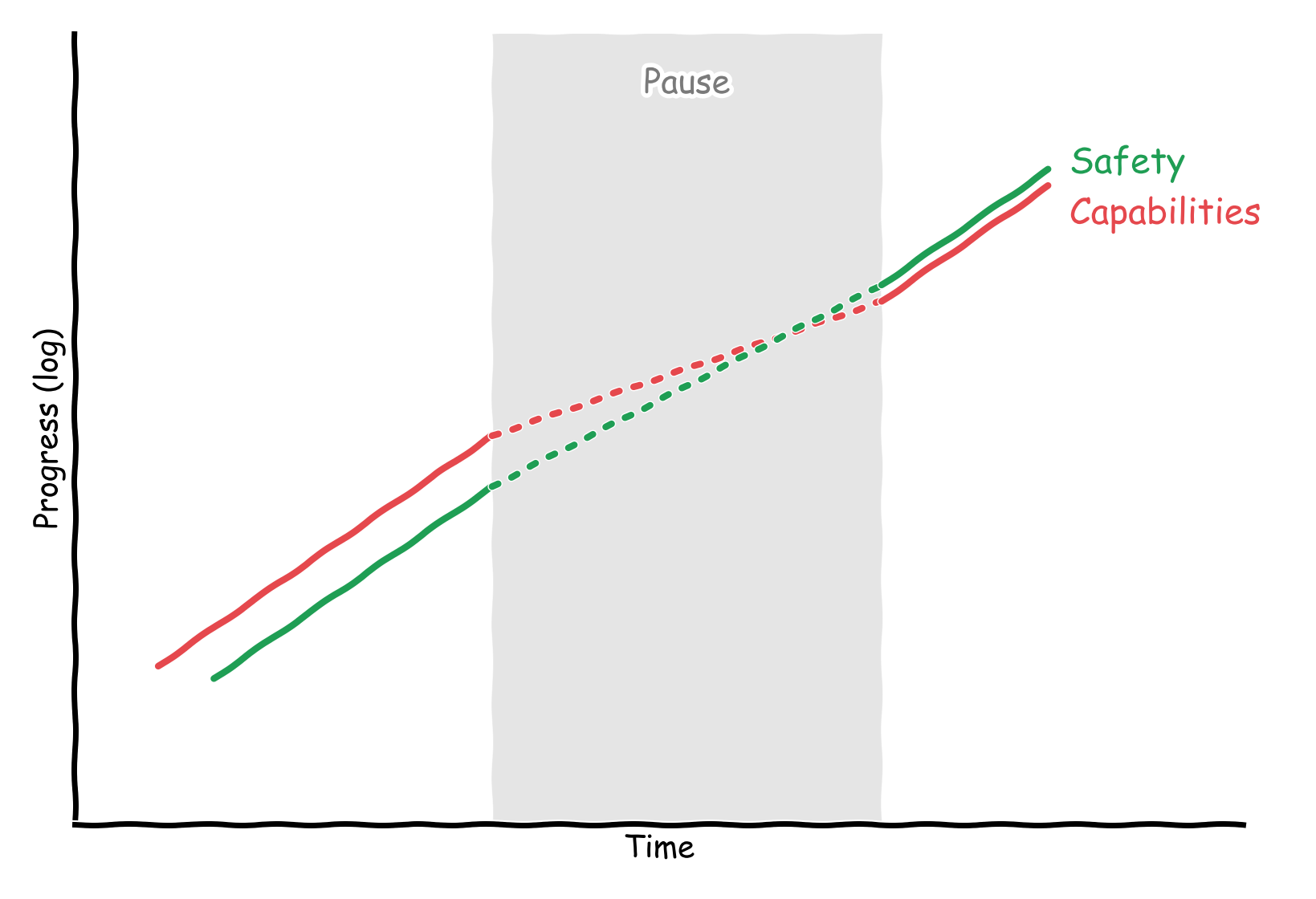
Measuring Safety Progress
How do you know if your current alignment techniques are working?
A Proposal
I don’t want this piece to be one where I dunk on possible pauses and instead put my money where my mouth is. In order for a pause to go successfully, I think I’d like to see a few things happen.
- Forecasting Safety Progress: We want to be able to predict a) the rate of progress of safety research b) how it compares to capabilities progress and c) scaling laws for safety progress, like we do with compute-capabilities scaling laws.
- Guaranteed, slow resumes: When we decide it’s an opportune time to resume AGI development, we should go slow; we can slowly scale up training models, training successively more capable models, and monitoring our alignment strictly. We can then
- Resumeable Pauses: We should give ourselves freedom to make a mistake and resume a pause; it’s important to do so in a way that isn’t abusable, but it probably reduces the risk of unpausing too early since you can pause again, and thus you increase the likelyhood of unpausing in general
- Accelerating Safety Research: The pause only works if safety research outpaces a potential overhang, and if forecasting finds safety progressing too slowly, we should find ways to accelerate safety research.
The actual pause, then, would look like the following:
- Labs Keep Inference Compute: Models are good for the world - labs should serve them
- We should enforce no-training through verification: Labs shouldn’t be able to own training compute
- Labs Should Dedicate Much of Current Training Compute to Safety: Enforcing this is probably difficult, but OpenAI’s past superalignment efforts are a good inspiration, dedicating 20% of organization compute to safety research with the rest used on inference. Some alignment and finetuning efforts need training, and this can be done in sandboxes with transparency to auditors, either through ZKPs or through third party auditors with access to all code and data in the sandbox.
Their entire proposal can be found here, but I don’t think the rest of the proposal addresses the concerns that I pose. I am not trying to strawman their proposal, and if you think that I am please do let me know.
This is a rough oversimplification, and I expect the overhang to be larger than this. Consider the situation where labs are still inference providers, and can optimize inference through either hardware or software. If the status quo is recursive self-improvement, this optimized inference would boost the pace of capabilities progress greatly.